
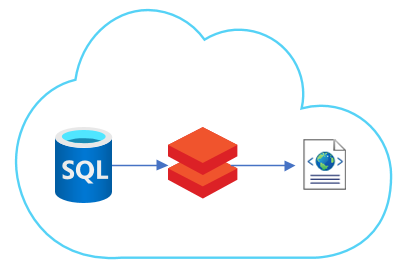
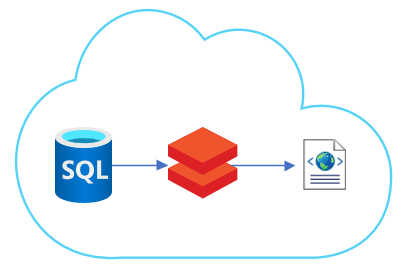
Task: Export data from Azure SQL database to XML file.
We have an Azure SQL database and we need to export data from it in the form of an XML file.
There is a couple of ways how to create XML file:
- SQL server: SQL server can nicely save result of query to XML but then saving the file to ADLS is a difficult. I didn’t find easy way how to do it.
- Azure Function: Undoubtedly the best way. A simple script for generating XML would suffice. But it would cost quite a lot of research (for me) and I didn’t want that :-).
- Aure Data Factory: Unfortunately, XML is not a supported format. A supported format is JSON, for example. (At the time of writing, there was XML file option in outup dataset. After I solved the problem, this option was added to the ADF.)
- Logic App: There can be JSON converted to XML. So we can combine ADF and Logic App.
- Databricks: Yes, in scala is library which can convert dataframe to XML and it can save it. But it is not almighty. There can be one root node and then only row nodes on one level. But XML can be prepared in plain text form and then saved as XML (via plain text save method).
So final solution is in databricks. At least for now.
Azure Databricks
Although there is a library for working with XML files, if you need to create a more complex document, which does not consist only of the root element and then of individual line elements, then some manual work must be added.
The main idea is to prepare all the important parts of XML separately. The declaration, the tag for the root element, the header, the main data part itself and the footer.
We’ll need a few libraries for all the fun. The main is library com.databricks:spark-xml_2.11:0.9.0 and you can find it in maven.
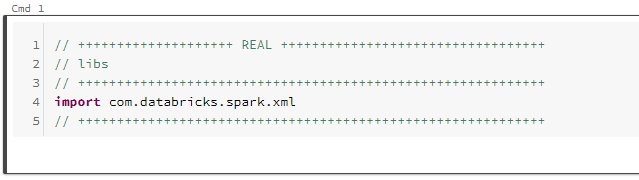
Declaration
The XML declaration is a processing instruction that identifies the document as being XML.
Example: <?xml version=”1.0″ encoding=”UTF-8″ standalone=”no” ?>
XML declariation does not contain any variable so we can use the classic string value. It’s the same for XML root tag which is formed with start tag parXmlMainElementStart and end tag parXmlMainElementEnd.
parXmlRootTag is for main data and parXmlRowTag is tag for rows in main dataset.
val parXmlDeclaration: String = “<?xml version=’1.0′ encoding=’UTF-8′ standalone=’yes’?>”
val parXmlMainElementStart: String = “<mainRoot>”
val parXmlMainElementEnd: String = “</mainRoot>”
val parXmlRootTag: String = “inquiries”
val parXmlRowTag: String = “inquiry”The document header is also a standalone value.
val xmlHeader =
<header>
<version>1.1</version>
<firmNumber>NY01017T</firmNumber>
<datetime>20200815</datetime>
</header>We now have constant values ready. Now just prepare the row data itself. You need to have the data loaded in the dataframe. Then all you have to do is call the write method.
parDfInputData.write
.format(“xml”)
.option(“rootTag”, parXmlRootTag)
.option(“rowTag”, parXmlRowTag)
.mode(“overwrite”)
.save(“dbfs:/mnt/export/data”)This saved an XML document with the line data itself. A new directory has also been created that contains xml data in a file named part-000000. You only need to use the contents of this file and glue it all together with the rest.
So we load the just created XML document as an ordinary text file into a text value.
val fileContents = Source.fromFile(“/dbfs/mnt/export/data/part-00000”).mkStringAnd let’s put it all together.
val txtFinal = parXmlDeclaration + parXmlMainElementStart + parXmlHeader + “\r\n” + fileContents + parXmlMainElementEndNow we will save XML document as a plain text file.
dbutils.fs.put(“dbfs:/mnt/export/data” + “.xml”, txtFinal, true)And finally we clean up, the unwanted directory, after ourselves.
val directory = new Directory(new File(“/dbfs/mnt/export/data/” ))
directory.deleteRecursively()In the end you can create function for creating XML documents from sql database. But that will be in the next post :-).
