

Nečekejte nic převratného, jen na základě zdrojového datasetu jsem vytvořil krátký bojový plán jak se s daty vypořádat a dostat z nich nějakou přidanou hodnotu.
Je to cca 3h práce, takže to není dokonalé, ale snad alespoň nosná myšlenka je správně zachycena.
Postupně budu přidávat a předělávat, aby mohla posloužit (ta case study) jako reference pro tvorbu malého, milého reportingu (i s datovým zpracováním).
Zdroj dat
URL: https://archive.ics.uci.edu/ml/datasets/online+retail#
Retailová data v transakční podobě, nejspíše podmnožina / extrakt z objednávkového systému. Data obsahují online objednávky, většinou velkoobchodních, zákazníků v prodejnách registrovaných v UK. Prodejním artiklem jsou nespecifikované dárky (prostě taková všemožná veteš). Data jsou uložena v excelu.
Co s daty
Prozkoumat. Navrhnout způsob jak data zpracovat, vytěžit a zreportovat.
Vše je o kontextu. Ten tu ovšem chybí. Pokud v průběhu průzkumu vyvstanou nějaké otázky, zaznamenat.
Řešení
Excel není zrovna neprůstřelný datový zdroj. Je náchylný na lidskou chybu (pokud je do něj zasahováno ručně) a i technický zápis do excelu může produkovat různé chyby. Každopádně, pokud jsou data dostupná přímo ze zdroje (relační databáze), bylo by lepší brát data přímo z něj, případně zvolit jiný formát exportu (json, xml). Ano, mohli bychom vést diskuzi jestli excel patří mezi strukturovaná data a není tak lepším zdrojem než semi-strukturovaná data (json a xml).
Hraje zde roli více faktorů : objem dat, četnost exportu, existence případného xslt pro validaci, typ cílového úložiště (kdyby to byla dokumentová databáze tak je json ideál), atd.
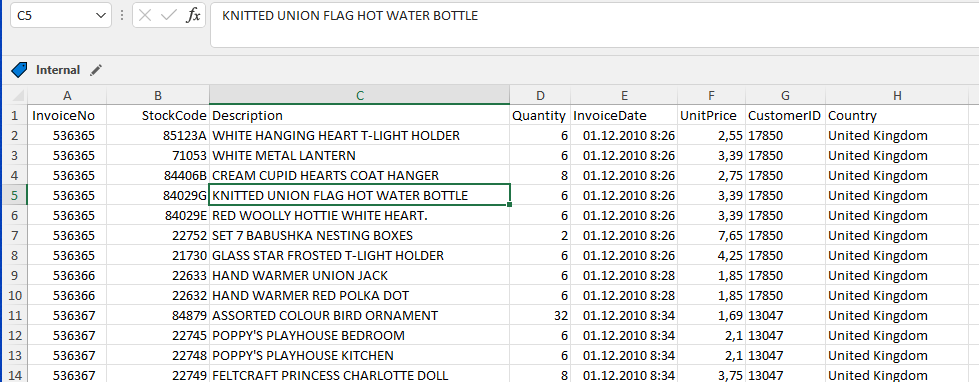
Seznámení s daty
- Nejdříve otevření v excelu. Jednoduchá kontrola konzistence dat. Jaké jsou kde datové typy, jestli nejsou hodnoty mimo pojmenované sloupce.
- Následné načtení excelu do PWBI. Volba datových typů atributů dle popisu dat na webu.
- Identifikace datových nejasností/chyb.
InvoiceNo
- Číslo objednávky, integer.
- Prefix označuje stav objednávky. “C” značí zrušenou objednávku. “A” nějaký administrativní úkon “Adjust bad debt”.
- Všechny řádky mají atribut vyplněn.
StockCode
- Dle popisu dat by mělo jít o číselný identifikátor, ale obsahuje i písmena (12% hodnot neodpovídá číselnému formátu).
- Dle dat to vypadá na písmenné označení variant produktu = písmeno na konci kódu.
- Dále tam jsou kódy typu “D”, “M”, které označují nějakou administrativu = kategorizovat.
Description
- Popis produktu, text.
- Není vždy vyplněn.
- Opět obsahuje administrativní popisy, nejen popisy produktů.
Quantity
- Množství produktů v objednávce, integer.
- Hodnota je vždy vyplněna.
InvoiceDate
- Datum a čas objednávky, datetime.
- Hodnota je vždy vyplněna.
UnitPrice
- Cena za jeden kus produktu, decimal (2 desetinná místa).
- Některé hodnoty jsou záporné – objednávky s prefixem “A”.
- Některé produkty mají cenu nulovou – něco jsou odpisy (záporné množství a odpisový popis), ale nulová UnitPrice je i u jinak validních dat (správný kód produktu, množství, popis).
CustomerID
- Identifikátor zákazníka, integer.
- U cca 25% případů není zákazník vyplněn. U odpisů a admin věcí není vyplněn, ale není vyplněn i u validních dat.
Country
- Název státu zákazníka, text.
- Vyplněn vždy.
Zrušené objednávky (prefix “C”) mají záporný atribut Quantity (nejspíše oprava pro skladové zásoby). V seznam objednávek nejsou jen objednávky, ale i administrativní úkony DOTCOM POSTAGE, AMAZON FEE, Manual, atd.
I nezrušené objednávky mají záporný atribut Quantity. Podle popisu produktu to vypadá o vyřazené zboží (“mouldy, unsaleable.”, “Damaged”, atd.).
Bylo by vhodné nějak toto identifikovat a rozkategorizovat ať se v reportingu nepletou mezi skutečné objednávky = přes stav objednávky. Nutná konzultace s vlastníkem dat.

Zdrojová data nejsou moc pěkná. Pokud by bylo možné ze zdroje vyrazit více informací, zejména co se týká kategorizace, tak by to značně zlehčilo práci s daty. Jinak se tyto informace budou muset vyrazit z vlastníka dat a kategorizace bude udělána na straně DWH/BI.
Nedostatky ani nejsou datové chyby, spíš je nedokonalý dodaný popis dat.
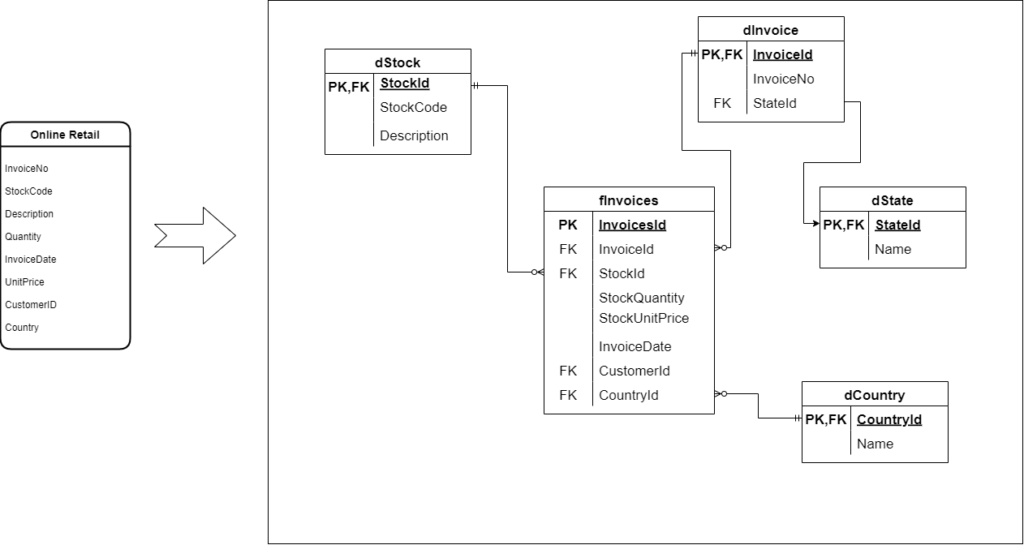
Model dat
Rozhodit do vločky (kvůli relaci mezi dInvoice a dState). Nad tou se bude reportovat. Ze zdroje se vygeneruje jedna faktovka a ctyři dimenze. S tímto modelem se počítá pro všechny varianty řešení reportingu.
dInvoice
- InvoiceId
- InvoiceNo
- StateId
fInvoices
- InvoicesId
- InvoiceId
- StockId
- StockQuantity
- StockUnitPrice (cena produktu v momentě prodeje, dá se dát do dimenze dStock, ale na to je málo informací)
- InvoiceDate
- CustomerId
- CountryId
dState
- StateId
- Name
dStock
- StockId (umělý klíč)
- StockCode (přirozený klíč)
- Description
dCountry
- CountryId
- Name
Datové kontroly
Data musí být v nějaké základní čistotě. Pokud budou některé důležité atributy chybět nebo budou nevalidní nebude možné data zapracovat do DWH. Kontroly se vyhodnocují přímo nad zdrojovými daty. Výsledky kontroly se reportují odpovědnému vlastníkovi zdrojových dat. Přítomnost datových chyb může ovlivnit výslednou datovou analytiku (vyjdou jiné součty, počty, atd.).
Kontroly je možné zařadit do kategorií podle typu jejich “obsluhy”. Např. “soft” = chyba za zaeviduje a data se pustí do DWH (něco jako warning), “hard” = chyba se zaeviduje a data se nepustí do DWH (něco jako error). Seznam chyb by měl být dostupný v reportu nad daty, aby bylo vidět jaká data se do reportu nedostala a proč (hard) a na co si dát pozor (soft). Je to součást interpretace reportu (proč se neukazují všechny objednávky, proč je suma tržeb jiná než by měla). Kategorizaci je nutné probrat se zadavatelem.
InvoiceNo
- Je vyplněno? hard
StockCode
- Je vyplněno? hard
Quantity
- Je vyplněno? hard
InvoiceDate
- Je vyplněno? hard
- Je datum validní? Není v budoucnu či moc v minulosti? soft
UnitPrice
- Je vyplněno? hard
- Je číslo vyšší než 0? soft
- Není číslo až moc velké (nějaký limit)? soft
CustomerID
- Je vyplněno? soft
Otázky
- Kolik procesního výkonu chceme na zpracování obětovat?
- Kam a v jaké podobě se budou data ukládat?
- Použití ETL či ELT?
- V čem bude probíhat zpracování, transformace (sql, databricks, ssis, pwbi, atd.)? Co je k dispozici?
- Budou data historizována? Pokud ano, tak na jaké úrovni SCD, případně skrze nativní temporal v rdbms?
- Bude výsledná data, prohnaná “DWH + BI”, možnost porovnat s primárními daty (datové kontroly)?
- Jak často se data aktualizují?
- Jací uživatelé budou data/reporting konzumovat? Bude jim dovoleno pracovat s daty na úrovni tvorby/úpravy datasetu, tzn. pustíme je do podkladových dat?
- Do jaká míry budeme ručit za výstupy nad daty (jde o věcnou správnost)? Pokud ručit budeme, musíme omezit uživatele, aby si tam nevytvářeli vlastní “výpočty”.
Konkrétní doporučení, závěry a návrhy by byly až po zodpovězení otázek. Takto bude řešení obecnější.
Reporting bude realizovaný v nástroji Microsoft Power BI. Je počítáno s nahráním reportu do online tenantu. Klidně by šlo nahradit reportem v Microsoft Reporting Services s publikováním na report serveru.
Varianta 1
Stupid simple
Uložit excel na ftp server, sdílený disk, OneDrive, SharePoint, pc/server s PWBI gateway a udělat nad ním PWBI. Při aktualizaci nahradit excel novou verzí v úložišti a provést refresh v PWBI. Úložiště musí být dostupné z PWBI online service.

Varianta 2
Cloudový pohled – Simple and cheap
Uložit excel do datalake. V ADLS udělat složku actual kde bude vždy aktuální excel s fixním názvem a složku history, kam se budou přesouvat starší verze excelu s přidáním třeba timestampu do názvu (ta se dá vytáhnout z časové značky uložení souboru do ADLS). Levná forma historizace na úrovni zdrojových dat.
Přímo nad souborem v actual složce udělat PWBI. Tím se budou data vždy aktualizovat z nejaktuálnější verze excelu. Transformace provést v PWBI. Z dat vygenerovat (power query) tabulky fInvoices, dInvoice, dInvoiceState, dStock, dCountry jak je uvedeno výše v části s modelem dat).

Varianta 3
Cloudový pohled – Enterprise
Excel načítat do stage vrstvy v ADLS, tam historizovat (v lepší struktuře než ve variantě 2). Data transformovat do DWH, případně rovnou do datamartu. Buď pomocí data flow v Azure Data Factory či v Azure Databricks. Struktura by byla stejná jako v předchozí variantě (dala by se přidat datumová dimenze). PWBI bude nad datamartem, respektive sémantickou/analytickou/reportingovou (jak tomu chcete říkat) vrstvou.
V PWBI nebudou potřeba žádné transformace. Pokud bude potřeba vytvořit nějakou measure, tak se udělá v datamartu. V sém/ana/rep vrstvě už budou správné business názvy pro reporting, takže v PBI se jen vytvoří model a vizualizace.
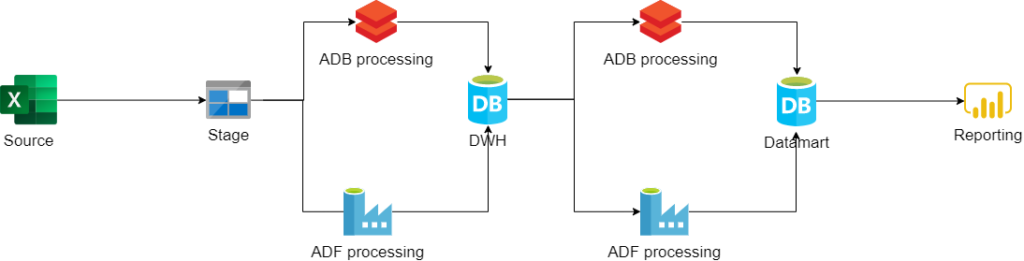
Varianta 4
On-premise pohled – Simple
Bulk insert přes SQL server přímo do SQL databáze do stage tabulky. Následná sql transformace do cílové podoby datamartu pomocí sql procedury. Pokud se excel bude aktualizovat pravidelně tak, pravidelné spouštění procky přes sql agenta na SQL serveru (+ aktualizace datasetu v PWBI). PWBI vytvořeno nad datamartem. V PWBI nebudou potřeba žádné transformace. Pokud bude potřeba vytvořit nějakou measure, tak se udělá v datamartu. Sémantická vrstva bude v PWBI.

Varianta 5
On-premise pohled – Enterprise
SSIS balíček s načtením dat z excelu, následné transformace do DWH a pak transformace do cílového datamartu. Transformace opět za použití SQL procedury. PWBI vytvořeno nad sémantickou/analytickou/reportingovou vrstvou.
V PWBI nebudou potřeba žádné transformace. Pokud bude potřeba vytvořit nějakou measure, tak se udělá v datamartu. V sém/ana/rep vrstvě už budou správné business názvy pro reporting, takže v PBI se jen vytvoří model a vizualizace.

Řešení “Simple” nepočítá s již vytvořenou enterprise architekturou. Nezačleňuje tedy zpracování dat do již existujících procesů.
Řešení “Enterprise” již počítá s existující architekturou a je tedy nutné začlenění do již zavedených datových procesů (třeba DWH).
PWBI
Ve všech variantách je report vytvořen podobně.
Datový zdroj je excel, takže nepůjde o online data = import mód pro uložení dat + schedulovaný refresh v online tenantu PWBI. Výjimkou může být začlenění DWH a pak následné řízení refreshe dle zpracování DWH. Takové věci jako rozřazení atributů do složek, volba vhodných formátů datových typů, skrytí technických sloupců, atd. je samozřejmost.
Simple řešení – Veškeré potřebné datové transformace budou realizovány v power query přímo v PWBI. Sémantická vrstva bude v PWBI. Measury budou taktéž v PWBI.
Enterprise řešení – Veškeré potřebné datové transformace budou realizovány v podkladové vrstvě (datamart). Tzn. tabulky uvedené v modelu i potřebné míry (measures) budou vytvořeny pomocí SQL transformací v datamartu. Business názvy atributů budou v sémantické vrstvě nad datamartem v podobě views.
Pokud jsou data citlivější dá se použít RLS a omezit pohled uživatelů na data například skrze určité zákazníky či produkty.
Přístupová práva zde řešit nebudu. Nejvhodnější by bylo použít buď přímo Active Directory nebo Office365 skupiny pro řízení přístupů.
Vizualizace
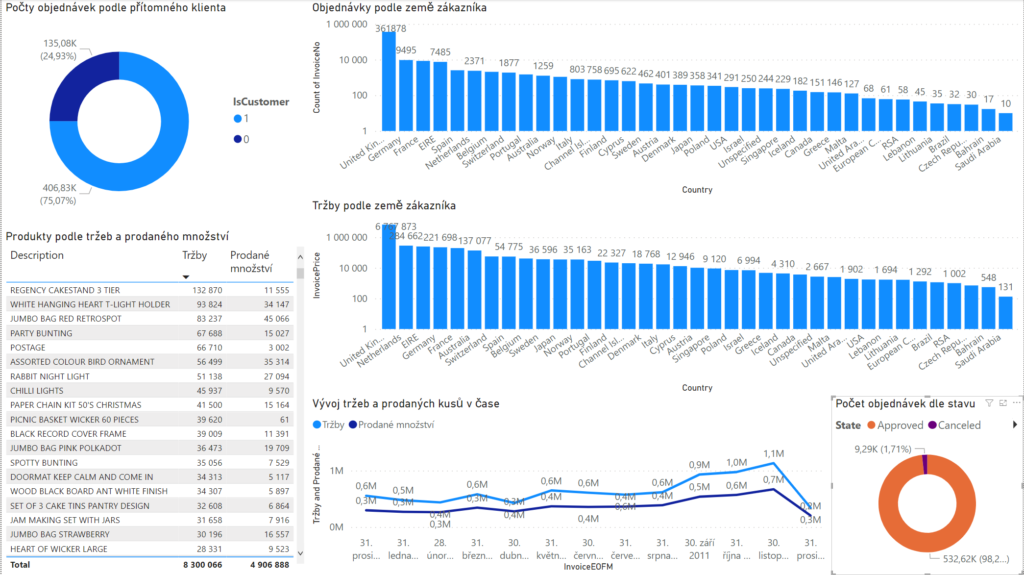
Skoro 25% jsou “administrativní” objednávky.
Nejvyšší tržby jsou “REGENCY CAKESTAND 3 TIER”, toto zboží má 1,6% podíl na všech prodejích.
Nejvíce se prodalo kusů “WORLD WAR 2 GLIDERS ASSTD DESIGNS”.
Nejvíce zákazníků pochází z UK. Holanďané jsou v počtu objednávek 6., ale co se týče utracených peněz, tak jsou 2. Co se na ně více soustředit?
Zároveň největší zákazník je z Holandska. Za sledované období realizoval 2085 objednávek za 279 489.
Od září jsou prodeje nahoru a největší prodeje jsou realizovány v listopadu. Prosinec je mrtvej. To je celkový přehled (ten asi bude táhnout příprava na Vánoce). Pokud se na vývoj podíváme přes jednotlivé státy, tak je nákupní chování v různých zemích jiné (možná vliv lokálních svátků).
